2023-07-06
以色列初创公司Hailo 的首席技术官兼联合创始人 Avi Baum 与 Nick Flaherty 讨论了Transformer AI 驱动其第三代芯片设计的不同用例。
“这个领域存在大量的术语误用,”Baum说。“Transformer 是自然语言处理 (NLP) 的主要构建模块,但现在它已被用于许多领域,例如图像、音频、文本等。这与 CNN 的补充一样重要,”他告诉eeNews Europe。
该技术已被用于通过对数据进行去噪,甚至通过使用第一代 Hailop-8 芯片重新创建视频会议的数字化身来减少 5G 无线电网络的带宽。“在 Hailo,在客户的推动下,我们对Transformer的支持随着时间的推移而不断增长,”他说。
据 Crunchbase 称,该公司是资金最充足的人工智能芯片设计商之一,筹集了 2.24 亿美元资金。3 月份推出的第二代芯片目前正在提供样品,正在进行调整以增加对 Transformer AI 的支持,这是正在开发的第三代架构的一个关键领域。
虽然 Transformer 是 Dall-E 和 ChatGPT 等基于云的生成式 AI 系统的关键,但它们也被用于 Hailo-8 处理器等嵌入式芯片的边缘图像识别。他说,关键是针对各个用例的云和本地处理的平衡。
“人们将生成式人工智能用于两种不同的用途,即根据文本提示生成新图像等内容。但我看到很多情况下,人们将 GenAI 扩展到具有LLM或多种模式的任何事物,以构建新时代的人工智能。这造成了很多混乱,”他说。
“就像早期的移动设备一样,我认为一般来说边缘和云将结合在一起构建一个更大的整体,因此每种类型的用例都将以有意义的方式进行划分。在某些应用程序中,正确的划分是将事物放在云中,因为它更可用,而其他部分则放在边缘。
他指出,用于监控安全摄像头的人工智能软件将生成式人工智能和使用变压器的图像处理相结合。
“你可以采用大型视频管理系统,例如监控摄像头,并通过文本提示找到某些图像,也许可以通过将LLM与在一个环境中理解所有摄像头的视觉效果的能力相结合来找到穿着特定衣服的人,”他说。
“部署此类用例的正确方法是使用相同的查询来查询场地中的所有摄像机,而不是将所有视频传输到一个中心点。然而,在云中创建相机可以理解的概要和嵌入要高效得多。另一方面,对于语音翻译,您可能希望在边缘设备上进行。”
视频会议是另一种潜在的组合。“你可以提供足够详细的头像,而不是提供视频,并通过客户端上的生成人工智能在本地机器上重新创建整个会说话的头像,”他说。
“我们将展示的另一个用例是使用人工智能对图像进行去噪——去噪版本在编码器上创建的带宽要低得多,”他说。“在我们的解决方案中,我们的客户正在使用基于变压器的物体检测。”
Transfrmer被用于标准物体检测,特别是在汽车领域。“最常见的一个性能问题是在给定工作负载下可以获得的准确性,Transformer在给定帧速率下提供了更好的准确性,主要是因为Transformer创建了这种注意的概念来查看图像的特定部分,并且可以给出比 CNN 更好的结果,”Baum说。
“我们已经展示了一款带有Transformer的单一设备,可以在 Hailo-8 上实时运行超过 6 个摄像头的全高清汽车配套设备,”他说。“归根结底,限制我们的是整个平台的资源。最终我们需要一个地方来存储所有模型。模型越大,性能越低,因此,如果我将模型大小加倍,粗略地说,性能就会减半。”
“但我们看到算法人员缩小了Transformer模型,而硬件制造商正在扩展平台。拦截点将会增长,直到我们达到云和边缘之间的良好平衡,但这需要几年的时间,”他说。
Hailo 是一种灵活的架构,具有一系列乘法累加单元,可以构建在任何工艺节点上,并且不依赖最新的前沿工艺技术来提高性能。
“我们构建的 Hailo 非常灵活,因为我们预先构建它时非常依赖编译器和工具链。展望未来,我们正在研究硬件的优化,对其进行一些调整,使其对变形金刚更加友好,以及我们认为变形金刚将发展成的样子。它足够灵活,但我们设计 Hailo-8 时没有考虑变压器。有些事情我们可以进一步改进,”他说。
“有很多特定于Transformer的东西,例如归一化函数的类型、动态权重快速变化的性质,最重要的是枚举,”他说。“每种类型的神经网络在每一层内外都有一个典型的张量跨度,这会随着变压器的变化而变化,因此可能需要调整一些参数,这就是我们正在做的事情,”他说。
“其中一些是我们在第二代中所做的,其中一些将在下一代中更加明显。路线图尚未完全确定,我们仍在讨论中。我们的核心技术是架构而不是技术节点,因此我们可以在当前的几何结构下做到这一点,我们可以根据目标市场选择做或不做。”
视觉Transformer挑战加速器架构
在快速发展的人工智能世界中,CNN 及其相关产品似乎很长一段时间以来一直在推动边缘人工智能引擎架构的发展。
该架构非常适合视觉处理,其中向量和标量操作类不会与张量层显著交错。一个过程从标准化操作(灰度、几何尺寸等)开始,通过矢量处理进行有效处理。然后是一系列深层层,通过渐进张量运算对图像进行过滤。最后,像 softmax 这样的函数(同样基于向量)对输出进行归一化。算法和异构架构是围绕这种假设的交错缺乏相互设计的,所有重型智能都在张量引擎中无缝处理。
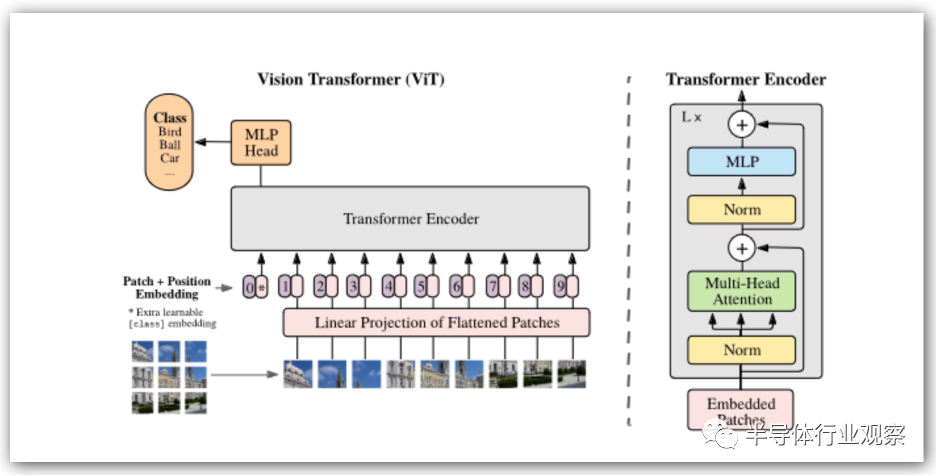
Transformer 架构由 Google Research/Google Brain 于 2017 年发布,旨在解决自然语言处理 (NLP) 中的问题。CNN 及其同类通过串行处理局部注意力过滤器来发挥作用。图层中的每个过滤器都会选择局部特征——边缘、纹理或类似特征。堆叠过滤器积累自下而上的识别结果,最终识别出更大的物体。
在自然语言中,句子中单词的含义不仅仅由句子中相邻的单词决定;某个距离较远的单词可能会严重影响解释。连续应用局部注意力最终可以从远处获得权重,但这种影响会减弱。更好的是全局注意力,同时查看句子中的每个单词,其中距离不是权重的因素,大型语言模型的显着成功证明了这一点。
虽然 Transformer 在 GPT 和类似应用中最为人所知,但它们也在视觉 Transformer(称为 ViT)中迅速普及。图像以块(例如 16×16 像素)的形式进行线性化,然后通过变压器将其处理为字符串,并有充足的并行机会。对于每个序列,连续进行一系列张量和向量运算。无论Transformer支持多少个编码器块,都会重复此过程。
与传统神经网络模型的最大区别在于,这里张量和向量运算是严重交错的。在异构加速器上运行这样的算法是可能的,但引擎之间频繁的上下文切换可能不会非常有效。
直接比较似乎表明 ViT 能够达到与 CNN/DNN 相当的准确性水平,在某些情况下可能具有更好的性能。然而更有趣的是其他见解。ViT 可能更偏向于图形中的拓扑洞察,而不是自下而上的像素级识别,这可能是它们对图像扭曲或黑客攻击更稳健的原因。ViT 的自我监督培训也正在积极开展,这可以大大减少训练工作量。
更一般地说,人工智能的新架构催生了大量新技术,这些技术在过去几年的许多 ViT 论文中已经很明显。这意味着加速器需要对传统模型和Transformer模型都友好。
来源:半导体行业观察